Valgrind suite tools introduction
The Valgrind suite tools (http://valgrind.org/) is a set of tools that are executed to perform different analysis of a program execution: time analysis, memory usage analysis, synchronization analysis and others.
Depending on the type of analysis to be performed, a different tool must be invoked from valgrind to analyze the execution. Current valgrind set include the following tools:
Memcheck: memory management analysis (i.e. memory leaks, invalid access).
Cachegrind: cache accesses analysis (instruction and data caches).
Callgrind: cycle estimation (time analysis).
Massif: memory usage analysis.
Helgrind: synchronization problems.
DRD: like helgrind but using less memory.
Other tools.
In this section we have included a brief description of some of the tools and the most common way to invoke them. Every tool include several options that could be helpful, but it is out of the scope of this section to detail every option for every tool. If more information is required for the analysis then it is recommended to check the full manual and specific sections for every tool.
Memcheck (http://valgrind.org/docs/manual/mc-manual.html )
This tool performs memory analysis of the program: memory usage, memory leaks and others. This tool detects reads and writes of invalid memory, using uninitialised values, deallocating invalid memory, memory leaks, and others.
To execute this analysis the tool parameter must be set to “memcheck”:
valgrind –tool=memcheck [memcheck options] dummy [program options]
The execution of memcheck is printed to the standard output and it must be redirected to a file in order to store the report. This report includes all possible problems related to memory, that is, not all issues included in the report are true problems. Memcheck reports all possible but some of them are just hints to the user that must review them.
Cachegrind (http://valgrind.org/docs/manual/cg-manual.html )
This tool performs memory cache analysis of the program by simulating the cache behavior (instruction and data caches). This is a very detailed analysis of the memory usage of a program and it is used to detect sections of the source code that potentially causes a lot of memory transfers that could degrade the program performance.
To execute this analysis the tool parameter must be set to “cachegrind”:
valgrind –tool=cachegrind [memcheck options] dummy [program options]
The information collected by cachegrind includes reads and writes access to the instruction and data caches, displaying the number of cache accesses and the misses access for every cache and level.
Once executed the analysis (that will run slowly) a summary will be printed summarizing the cache accesses. Also an output file will be created and it will store information that will be later parsed by the cg_annotate program. The default output file name is cachegrind.out.<pid> (where <pid> is the program’s process ID), but it can be changed by using the “–cachegrind-out-file” option.
Once created, the output file must be parsed by the cg_annotate tool as follows:
cg_annotate filename
The cg_annotate command accepts several options to format the output data. Check the cachegrind manual for further details.
Callgrind (http://valgrind.org/docs/manual/cl-manual.html)
This tool analyzes the execution of a program by counting the number of machine cycles spent by the program source code. This tool generates by default (can be changed using the callgrind option –callgrind-out-file) an output file named “callgrind.out.XXX”, where XXX is the program process id.
To invoke the tool the following command can be executed to analyze a program called “dummy”:
valgrind –tool=callgrind [callgrind options] dummy [program options]
The simplest way to invoke the program does not include any callgrind option and it generates the result in the default output file.
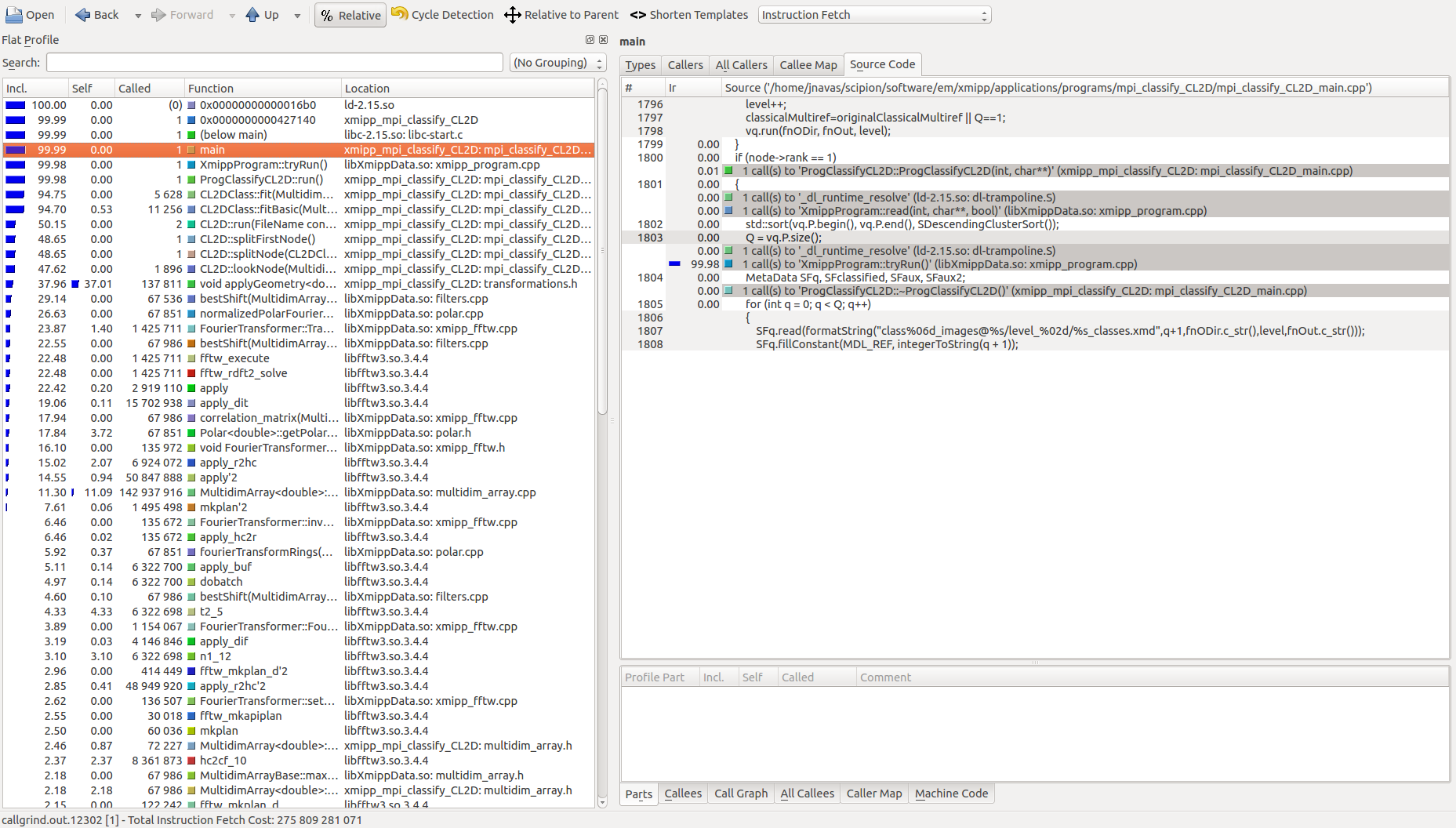
To visualize the output of the callgrind tool it is necessary to use the Kcachegrind tool (http://kcachegrind.sourceforge.net/html/Home.html). By double-clicking the file will be opened by KCachegrind and it would display all cycles information about the executed program.
The figure depicted below shows an example of a profiling displayed by Kcachegrind:
If the program being analyzed has created threads then one output file can be created for each thread. To generate them it is necessary to use a callgrind option called “–separate-threads” setting its value to “yes”.
valgrind –tool=callgrind –separate-threads=yes dummy [program options]
If this option is set to “yes”, then several files will be created, one per thread and another one for the main process. To analyze the report double click in the main process report and Kcachegrind will be opened displaying cycle information about the main process and all the threads. To view the information about any of the processes (main process or threads), select one of them in the “Parts Overview” located on the top left side of the Kcachegrind.
If the program to be executed uses MPI to be executed then it is necessary to include the valgrind call in the command line after invoking MPI. The way to invoke callgrind using MPI is included below (this invocation creates 4 MPI nodes, -np 4):
mpirun -np 4 valgrind –tool=callgrind [callgrind options] dummy [program options]
Valgrind generates a separated output file for evey MPI node and the reports must be visualized separately for every node.
These are the most common ways to invoke valgrind, depending on the type of execution (sequential, threads or MPI). For further information the callgrind manual should be reviewed.
Massif (http://valgrind.org/docs/manual/ms-manual.html )
Massif is a heap profiler. It measures how much heap memory your program uses. This tool is useful to analyze the amount of memory used by a program and to detect peaks of usage and where the memory can be deallocated as it is no longer used. By reducing the amount of memory allocated by a program the performance can be improved and also the memory requirements of the program can be reduced. This tool creates a report where the user can detect how much memory is in use and also what part of the source code allocated such memory.
To execute this analysis the tool parameter must be set to “massif”:
valgrind –tool=massif dummy [program options]
The report generated by massif is written to a file named massif.out.<pid>, where pid is the process program id. The output file name can be modified by using the “–massif-out-file” option.
Once generated the file, to visualize the information it is necessary to use the command “ms_print” that will generate a graph that contains the memory usage and also the source code responsible for allocating the memory.
ms_print filename
The graph printed is based in several snapshots taken by the valgrind at different time steps. The more snapshots taken the slower the analysis is executed (the default number of snapshots is 100). The image depicted below shows a graph created by massif:
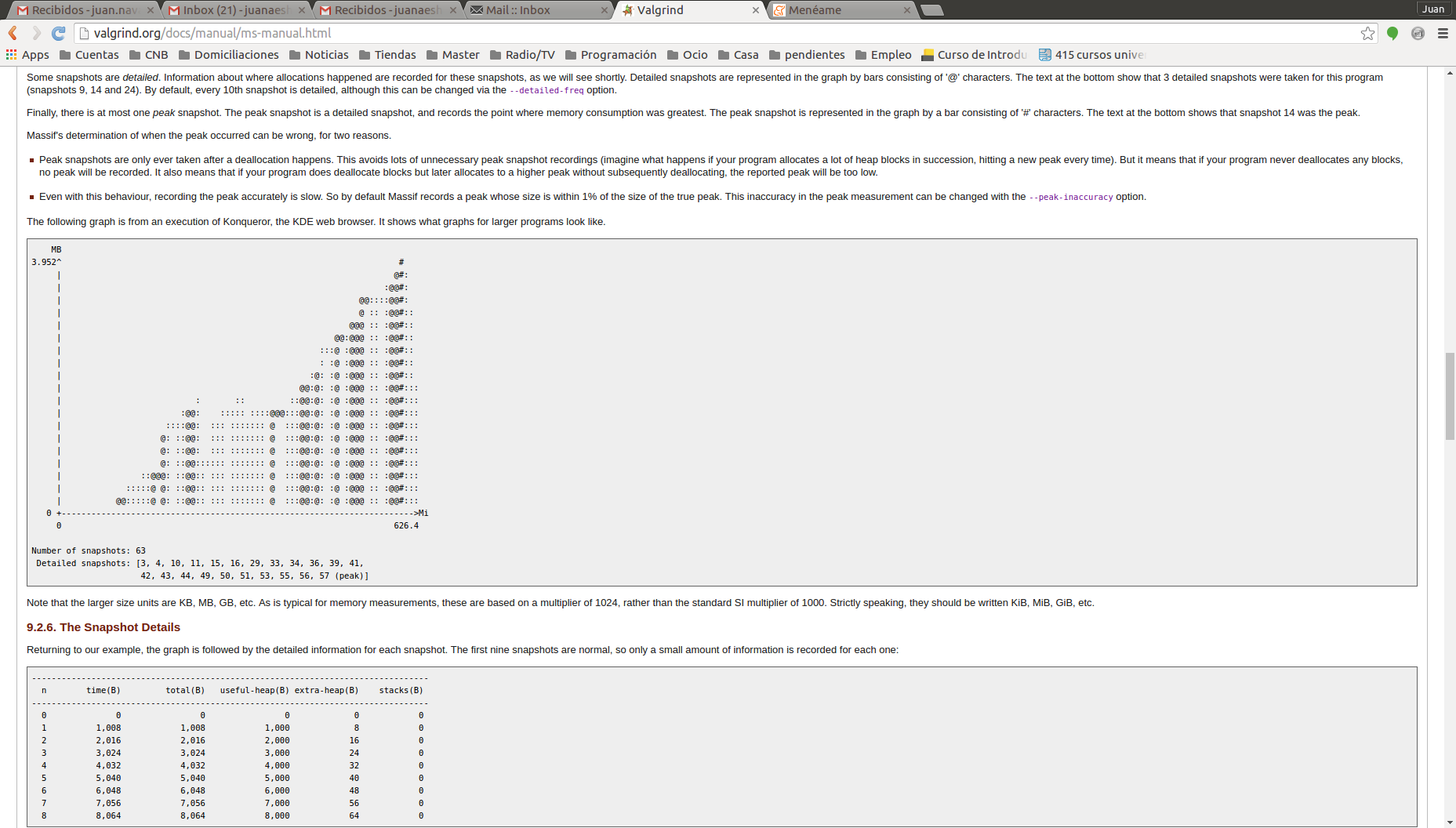
The detailed report contains the amount of memory allocated at every snapshot and for the detailed snapshots (‘@’ and ‘#’) it also includes the source code that allocated the memory, displaying a calling tree. If a snapshot is identified in the graph as a peak or it has allocated too much memory then it is necessary to find its snapshot id and find it in the detailed report included below the graph.
Helgrind (http://valgrind.org/docs/manual/hg-manual.html)
This tool performs synchronization analysis of the program by detecting synchronization problems that could arise by executing several threads. Helgrind can detect three type of errors: race conditions, deadlocks and misuses of the pthreads API (i.e. locking an invalid mutex). Problems like these often result in unreproducible, timing-dependent crashes, deadlocks and other misbehaviour, and can be difficult to find by other means.
To execute this analysis the tool parameter must be set to “helgrind”:
valgrind –tool=helgrind [memcheck options] dummy [program options]
The most common use of this tool does not require any option and the output will be printed to the standard output. If there are any problems during the execution of the program, the output includes the threads involved and the source code line where the problem has been found. Using this information the user must be able to “figure out” the synchronization problem and solve it.