Architecture
Overview
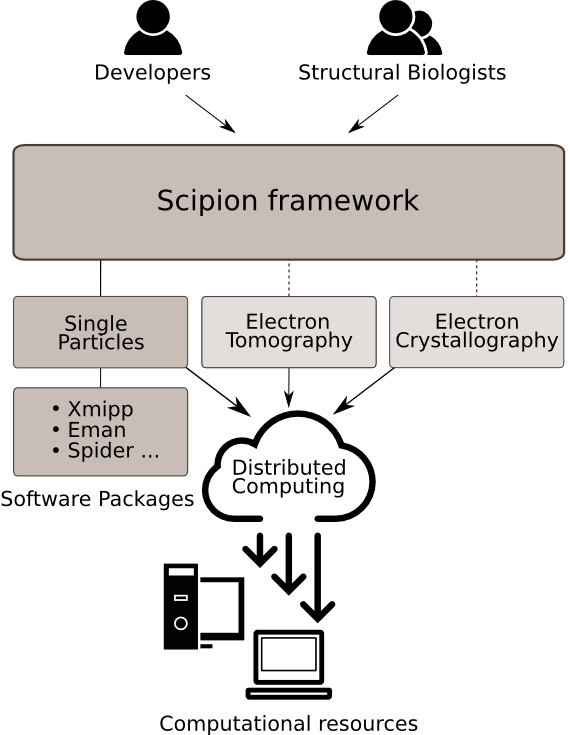
Scipion is an image processing framework for obtaining 3D models of macromolecular complexes using Electron Microscopy(3DEM) . It is designed to integrate several software packages in the field and present an unified interface for both biologists and developers. Scipion executes workflows that combine different software tools, while taking care of formats and conversions. Additionally, all steps are tracked and can be reproduced later on. The following diagram illustrates an overview of the Scipion framework.
Requirements
Main Goals
Scipion’s design and implementation is driven by its main goals:
Integration: Scipion should provide a common framework where different EM software packages can be used in the same project. The needed conversions (to move from one package to another) will run behind the scenes without bothering users.
Reproducibility: It is very important to enable the reproducibility and validation of published results. To meet this need, Scipion will track all image processing, storing all parameters used and the workflow executed. In that way, it will be possible to repeat a previous processing project starting from the original input data.
High Throughput: With the development of new devices, some steps are becoming more automated, such as data acquisition. Scipion should be able to execute workflows in an automated manner that will allow a better integration with acquisition systems.
Ease of use: Changing to a new system always requires effort from users – that’s one reason they tend to stick with packages they already know. Scipion should not be more complex to use than existing software packages, but it should provide extra functionality. We use graphical interfaces in order to improve the user experience.
Extensibility: Scipion should also be a framework for developers where they can find tools that facilitate the integration of new protocols. In order to succeed, we must engage developers from other groups to collaborate with us. We have tried to ease the learning curve to add new protocols, even for people without a computer science background.
Other features
We aim to:
Use existing file formats: No new image format should be introduced. The framework should use existing formats and ensure that the input for each operation is in the proper format. The input should be converted if needed.
Use a clear workflow: Each operation, or protocol, should have a set of well-defined inputs and outputs. This will allow the user to create a pipeline of logical operations following each other.
Share data and back up: Multiple users should be able to work on the same project and share results with collaborators. The system should also provide capabilities to perform intelligent incremental backups, only writing the files that differ from the previous backed-up state.
Make maintenance simple: The framework should be written in a modular way, divided into functional components. Each component should have a clear definition of its function and the how will interact with other components. The design should allow the user replace some particular component without affecting the whole system.
Components
The following diagram represents the main components that constitute Scipion. In the next subsections, we will explain each component separately.
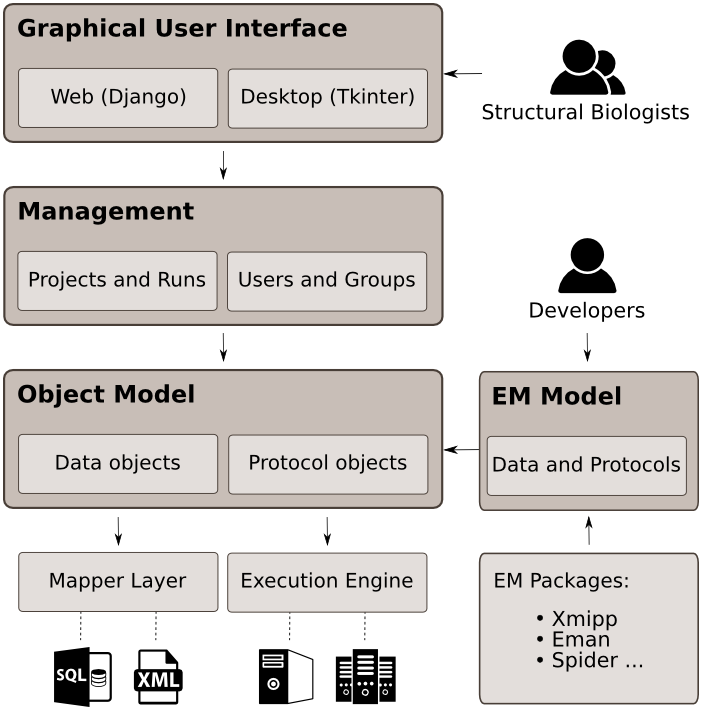
Object Model and Mapper Layer
All the Scipion framework is based on a basic object model
that wraps Python types. This model is defined in pyworkflow.object.
Object is the base class of all objects used in the model. The are two main types of
objects: Scalars and Compounds. The first type is for those objects that
hold a single value (such as String, Integer, Float, Boolean, and so on).
The compound objects are those that contain other objects. This base is used to model
the objects in the EM Domain. Read more more details about the Object Model.
We have used this basic model wrapping basic Python types to facilitate the
development of the Mapper layer to automatically store any type of object
(derived from Object).
There are 2 types of Mappers which main responsibility is to persist (store), and retrieve any Object derived from Object . Currently, both mappers in use are SQLite mappers and date ends up in SQLite databases.
The 2 mappers are:
Sqlite-mapper: Used to store any complex object like a project or a protocol. In general heterogeneous and complex objects. It’s a key value storage approach where the key is an attribute of an object, and the value is it’s value. It’s very flexible but not optimal for large sets like particles, averages, classes
Sqlite-Flat-Mapper: This is another approach to persist sets, in a more optimal way.
Protocol and Execution Engine
EM Model
Data
On top of this base, the objects related to EM were developed. Again, we
have two main types of objects: Data and Protocols. Data objects are the
inputs/outputs of the operations and they contain the underlying files and
formats used by each EM package. Examples of Data objects are: Image,
Micrograph, Volume,
CTF, SetOfImages,
SetOfMicrographs ..etc. Protocols
are the wrappers to the logical operations (such as: Filtering,
Alignment, Classification, Refinement…etc) which usually involve the
call to one or several command line programs. Protocols are in charge of
making the needed conversions and preparing files for calling the
programs. A protocol execution can be structured in different steps,
which are more atomic operations that can be resumed if the whole
process stops for any reason.
Protocols - Plugins
The object model makes it easy to integrate the plugins for different software packages. Plugins are installed using pip. Besides the regular pip package structure, Scipion plugins contain a folder with the following items (not all of them are mandatory):
__init__.py: Python-required file for a submodule. In this file we should define the Plugin class, which takes care of things like variables and installation of binaries.bibtex.py: contains the bibtex string literal as the Python doc stringconstants.py: Defines constants needed for the plugin and its protocols.convert.py: Converts from Scipion objects to files valid to programs. Also converts from results to Scipion.viewer.py: Creates tools to visualize results.wizard.py: Creates the wizards used.protocol__*.py: We recommend to prefix withprotocolall protocols implemented in the package.
For further information read our guide on How to create a plugin
Graphical User Interface
The Graphical User Interface (GUI) is an important part of each application. Having a nice and easy-to-use GUI will help users to focus on their tasks. In Scipion, the GUI presents a more intuitive and consistent way to launch programs and analyze their results instead of dealing directly with the command line.
There are five major types of GUIs in Scipion:
Manager window: The first window to open upon launching Scipion. Here, the user can see a list of all projects and also select, create, or delete projects.
Project window: The window where the users will spend the most time. Here, the users will launch new protocol executions, or runs, and manage the existing ones. For a selected run, more information is available in the lower half of the window in separate tabs for the input/output, the protocol citations and the log files produced by the execution. In the upper half of the window, it is possible to display the runs in either a list view or a flowchart view, where the relationships between among different runs are intuitively represented.
Form window: This is the second-most important window type. It is dynamically generated for each protocol and contains fields for each protocol’s parameters. This is convenient for developers when creating new protocols, because they only need to think about defining the input parameters and not about GUI programming.
Wizards: Wizards are simple and specific GUIs that assist users in selecting certain parameters. This normally saves time for users, since he/she can establish an idea of how a certain parameter will affect the results of a given operation before launching the job on an entire data set.
Data viewers: Visualization of data is essential to analyze image processing results. In Scipion, we have re-used some of the data visualization tools developed in existing EM software packages, such as Xmipp’s
showjand Eman particle picking. We have also developed some new tools, such as a web tool similar to xmippshowj, which is very useful for displaying tables, galleries of images, or volumes.
Management
The work performed in Scipion is organized by project. Each project has
its own folder (inside the `$SCIPION_USER_DATA/projects` directory)
and a separate database (project.sqlite). Each time the user
executes a new protocol within the project, it is registered as a new
run in the database. Thus, the user can check at any time which
operations have been executed so far, and the exact parameters used in each
step. Each run also contains its own folder (named as the protocol class
name and the run ID number) where all the outputs of the runs are located.
Scipion will have a user management system. Users will have permission to perform some operations on each project. It will also be possible to define groups of users, in which some properties and roles can be centralized.
Mapper layer
The Mapper layer is in charge of storing and retrieving objects. Our
main requirement for this module is to avoid a very complex database schema that
will be very hard to maintain and extend. Since we aim for an easy integration
of new packages and protocols, the Mapper will keep the
developer from dealing directly with databases or other type of storage. It
will provide an interface for storing, updating and retrieving objects
while hiding the implementation details and the underlying storage.
Currently we have implemented two mappers base on sqlite
(.../pyworkflow/mapper/sqlite.py). One of them is
designed to store objects’ relationships and easily insert new objects
without needing to create new SQL tables. Actually, there are only two
tables: Objects and Relations. The first one stores one row for
each Scalar object and several rows for Compound ones. The other
mapper implemented so far (although it is used less often) is based on xml;
it is less efficient for querying and iteration, but very convenient
for configuration files.
link:MapperImplementation[here]
Execution layer
Another added value of Scipion is the configuration of execution hosts and environments. The idea is that for one project, we can have a set of execution hosts, each one with their own capabilities. Then, while executing a Protocol, the user can choose the host that best fits the job’s needs. The data transfer to/from the execution host will be done by Scipion, so the user will not need to manually copy or move files. Currently, we have implemented the execution logic related to launching jobs to queue. Since each queue configuration varies among different systems, Scipion permits configuration for each execution host. The configuration of the queue and other settings should be done only once, while installing Scipion (probably with the help of system administrators), and the user will no longer need to set up and edit submission scripts.